Introduction to Gaussian Processes for Time Dependent Data
VectorByte Methods Training
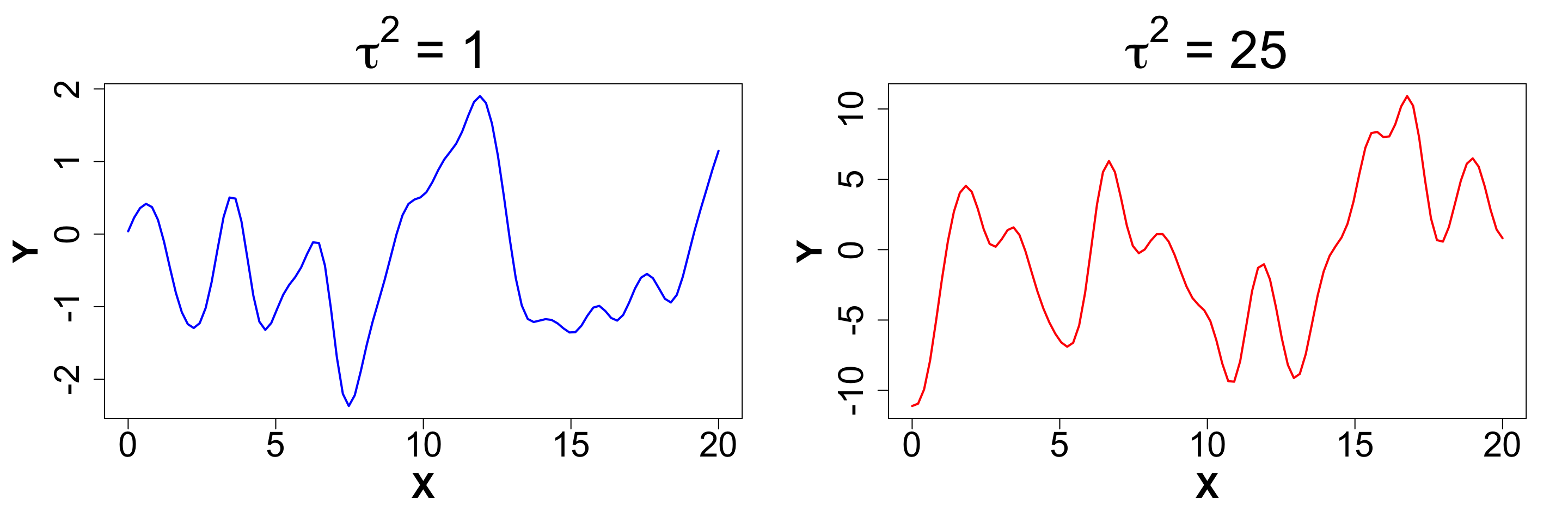
Scale (Amplitude)
A random draw from a multivariate normal distribution with \tau^2 = 1 will produce data between -2 and 2.
Now let’s visualize what happens when we increase \tau^2 to 25.
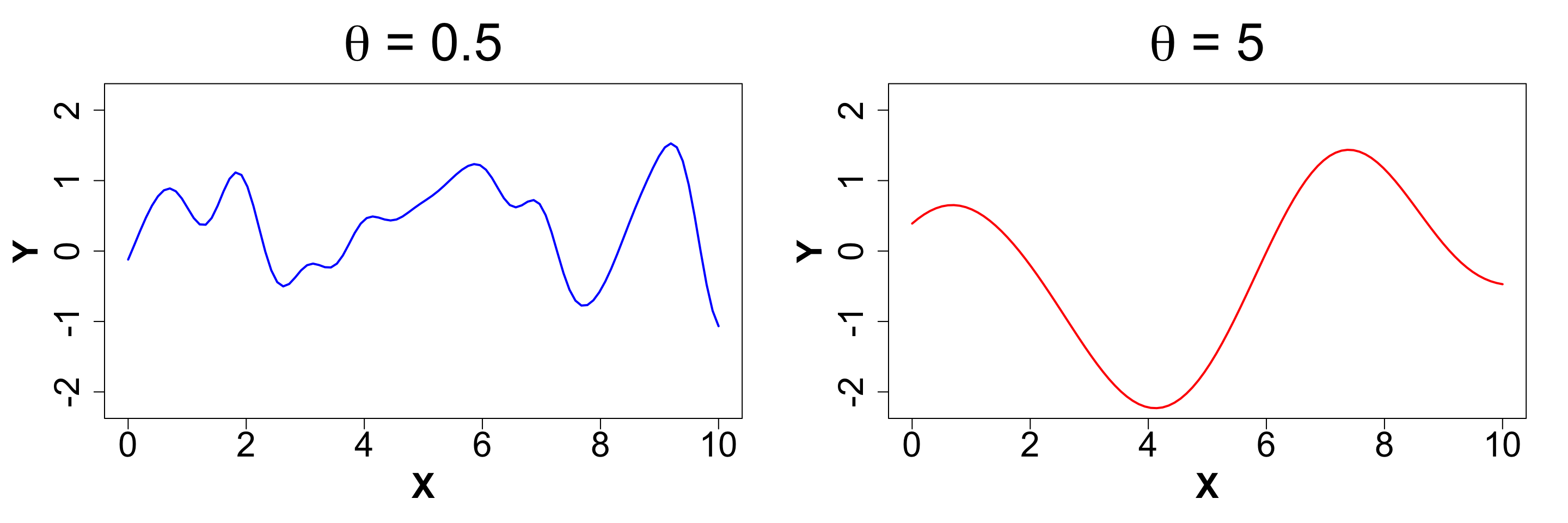
Length-scale (Rate of decay of correlation)
Determines how “wiggly” a function is
Smaller \theta means wigglier functions i.e. visually:
Nugget (Noise)
Ensures discontinuity and prevents interpolation which in turn yields better UQ.
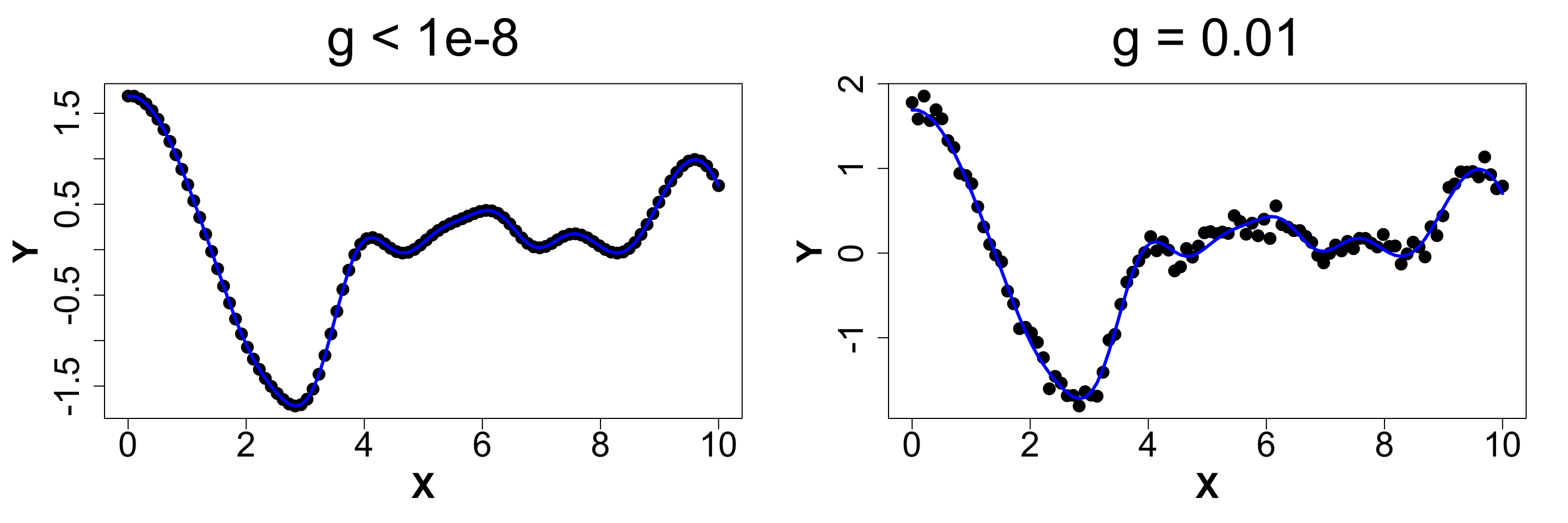
We will compare a sample from g ~ 0 (< 1e-8 for numeric stability) vs g = 0.1 to observe what actually happens.
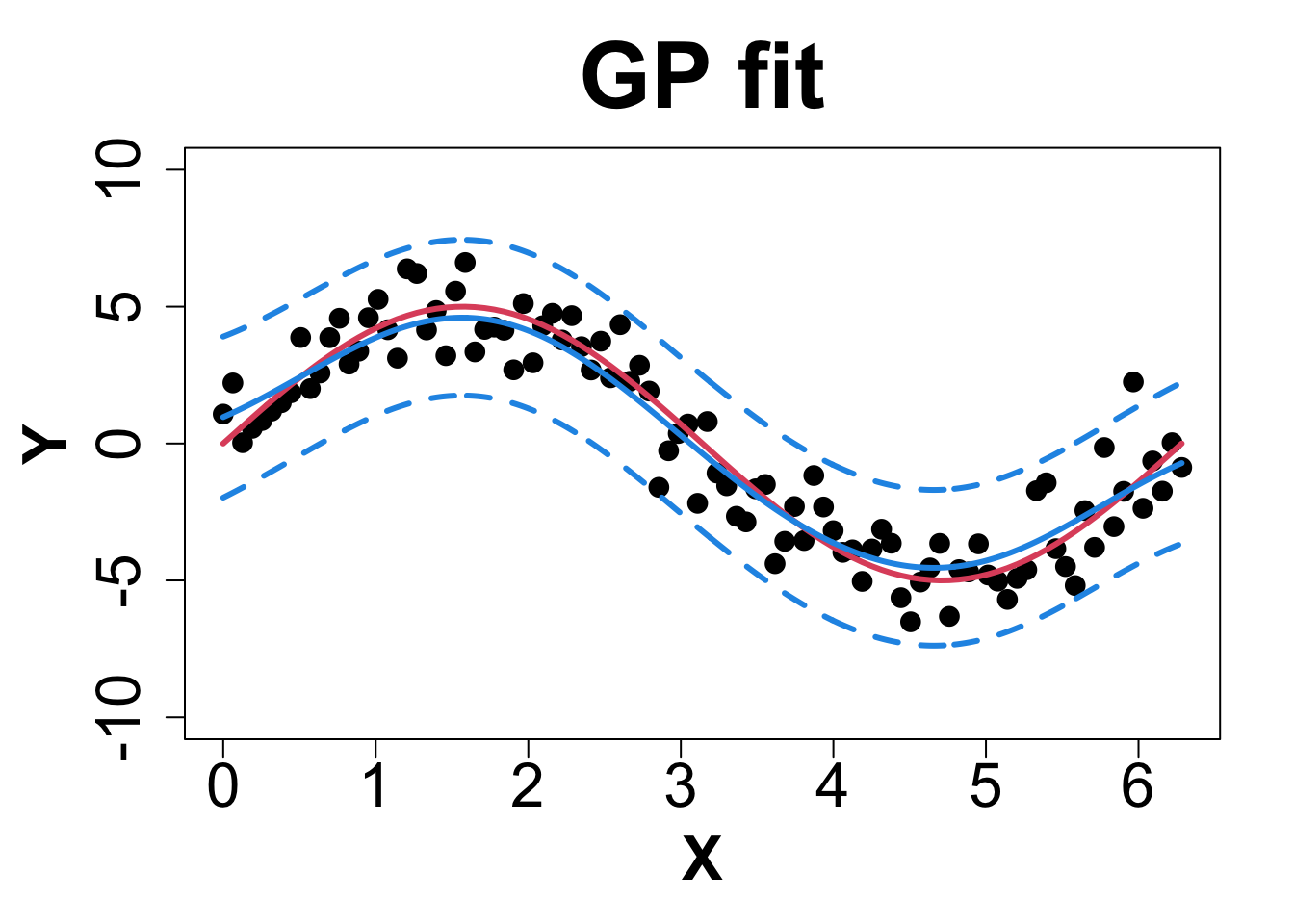
Toy Example (1D Example)
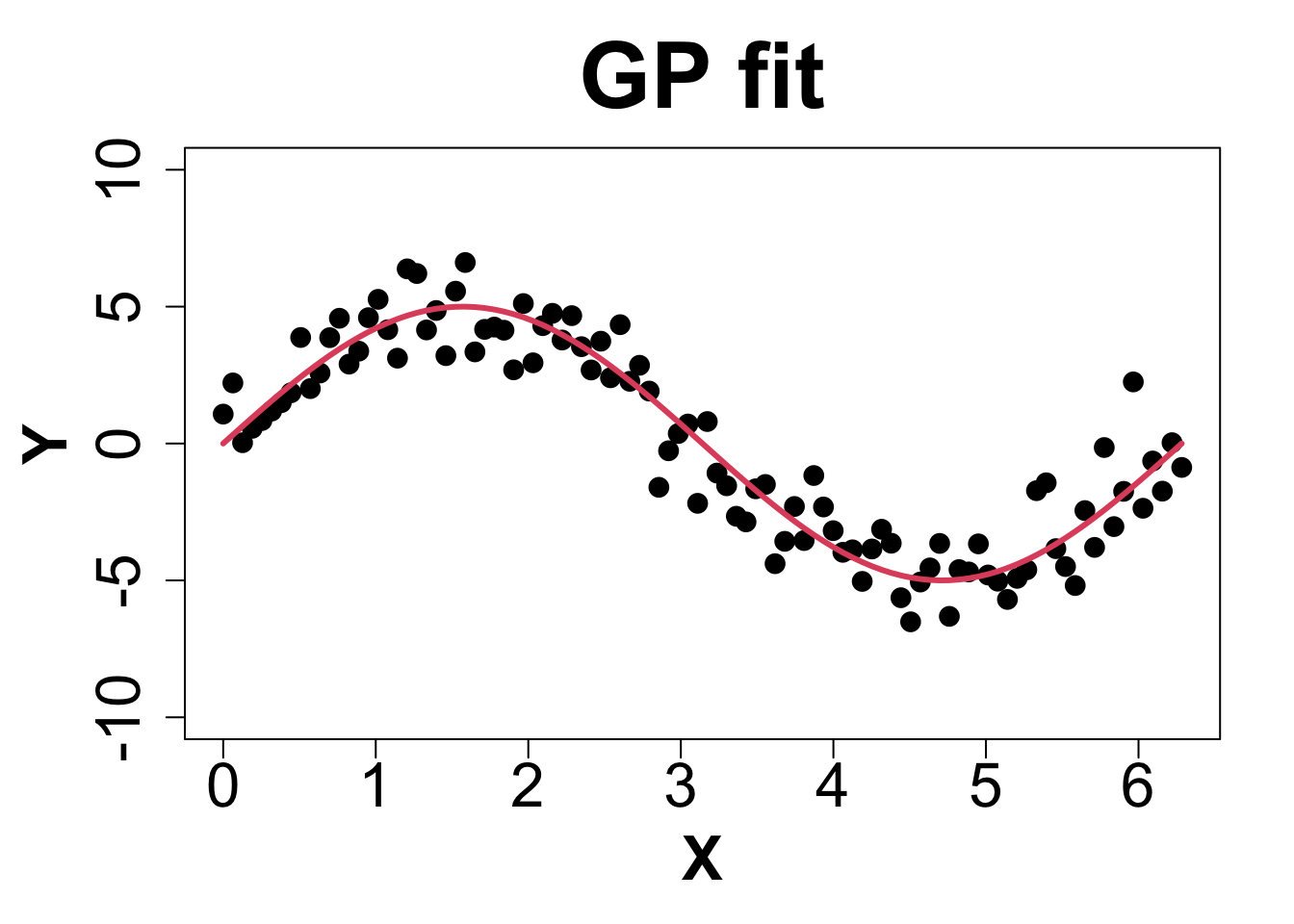
Toy Example (1D Example)
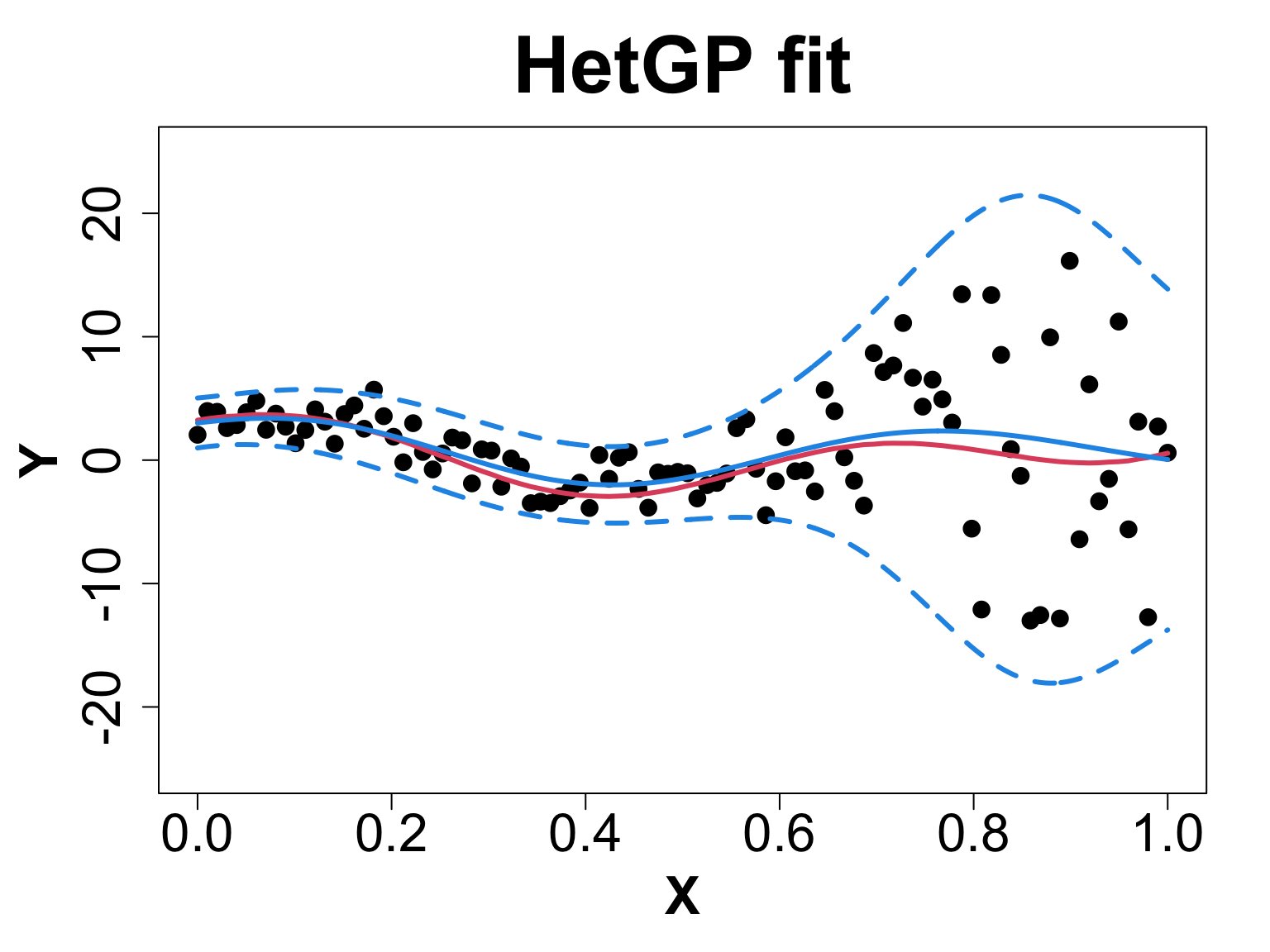
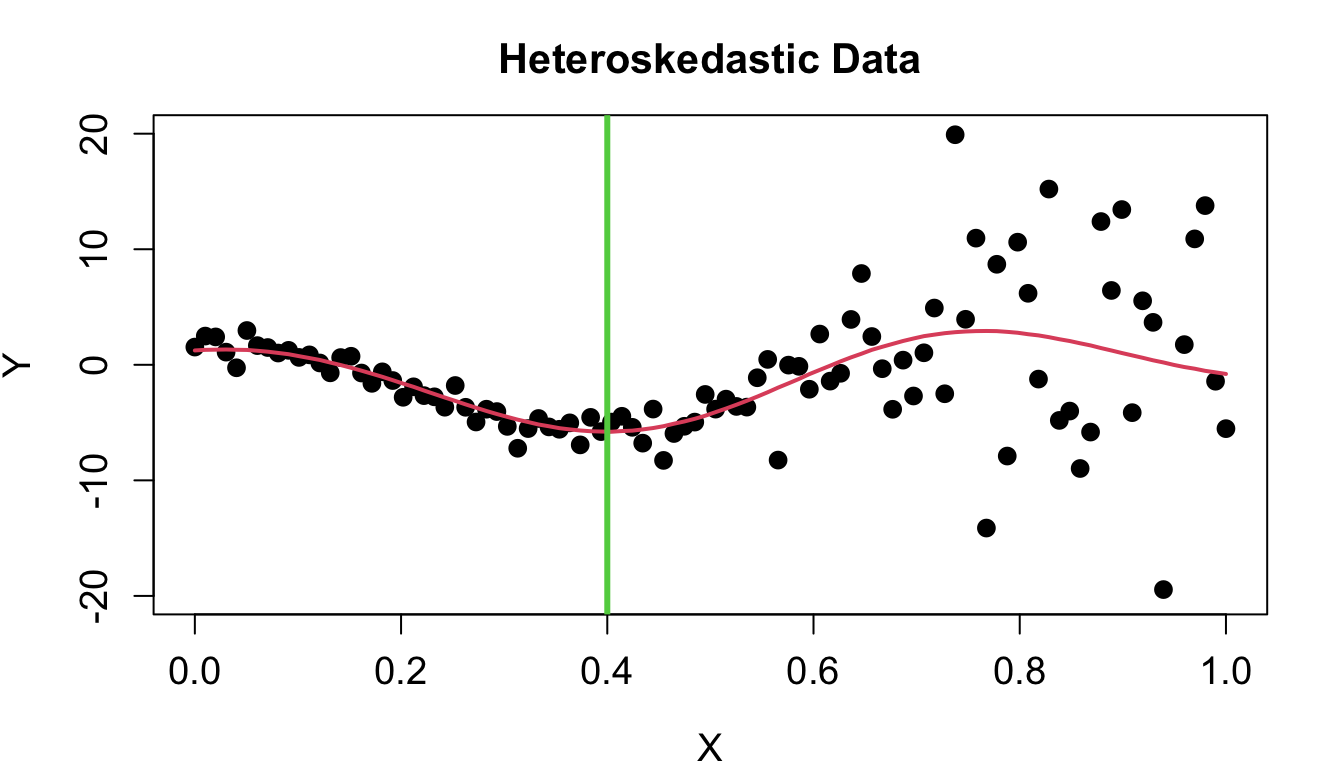
Heteroskedastic Gaussian Processes
- Heteroskedasticity implies that the data is noisy, and the noise is input dependent and irregular. (Binois, Gramacy, and Ludkovski 2018)
Toy Example (1D Example)

Toy Example (1D Example)
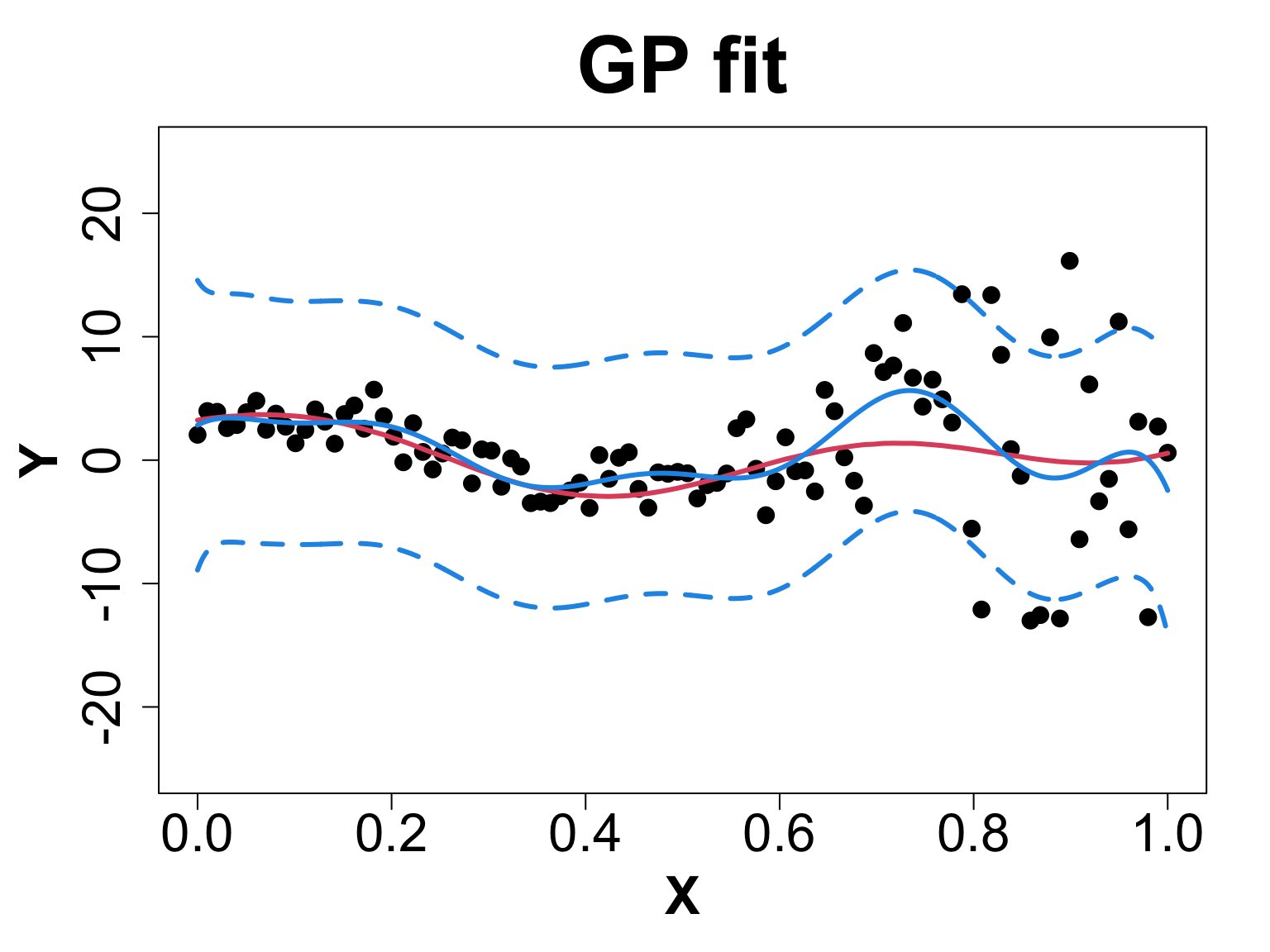
Toy Example (1D Example)