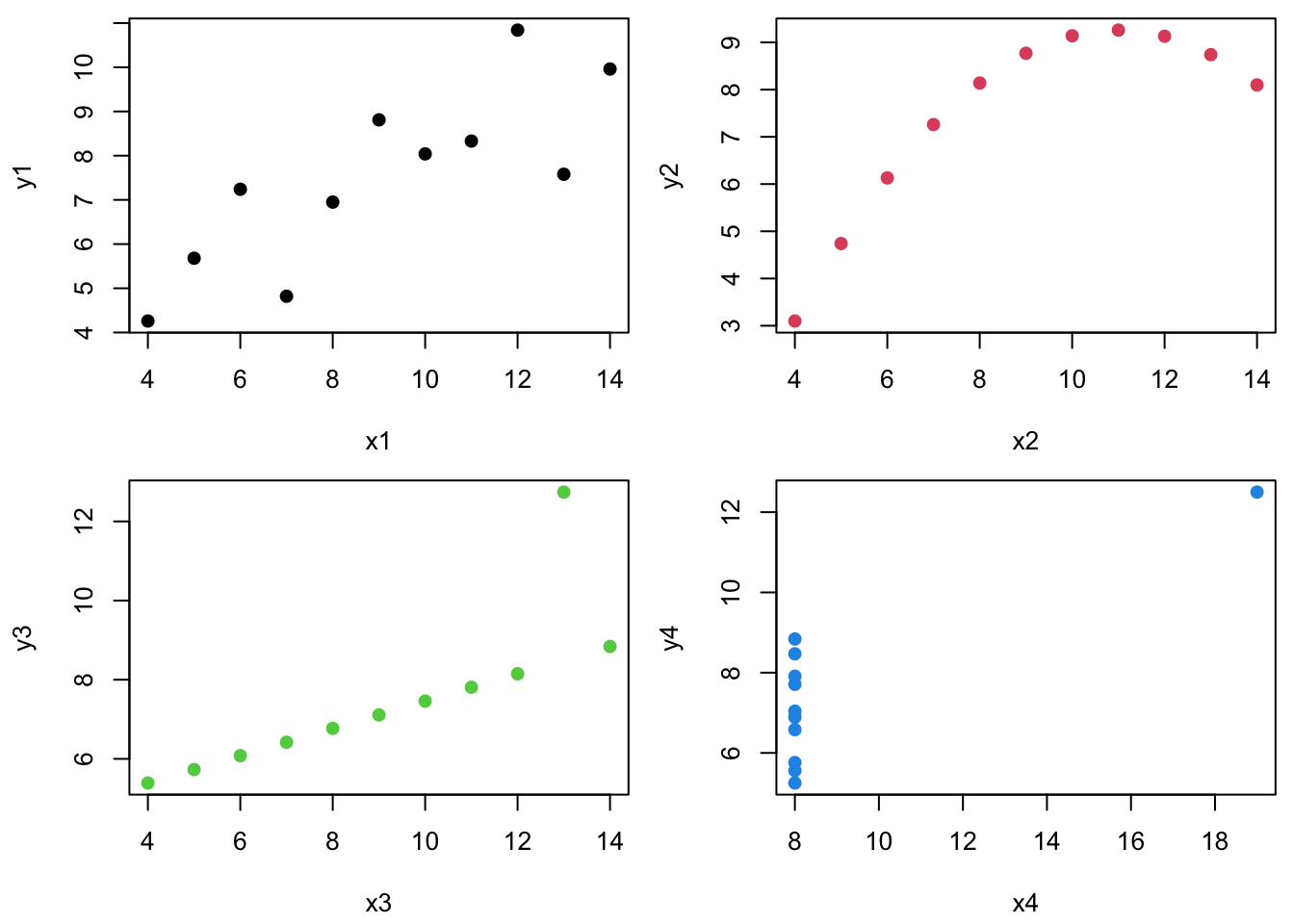
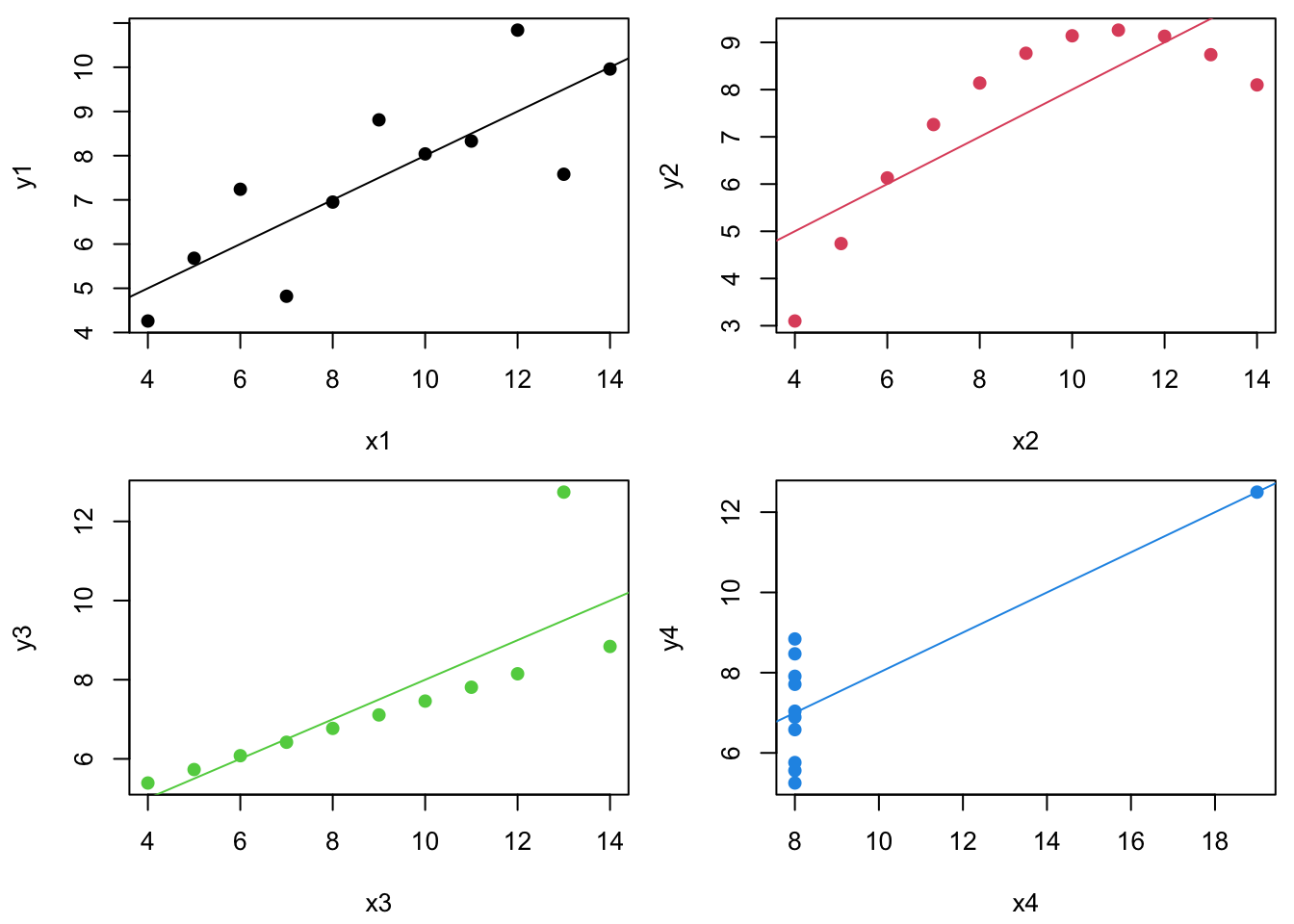
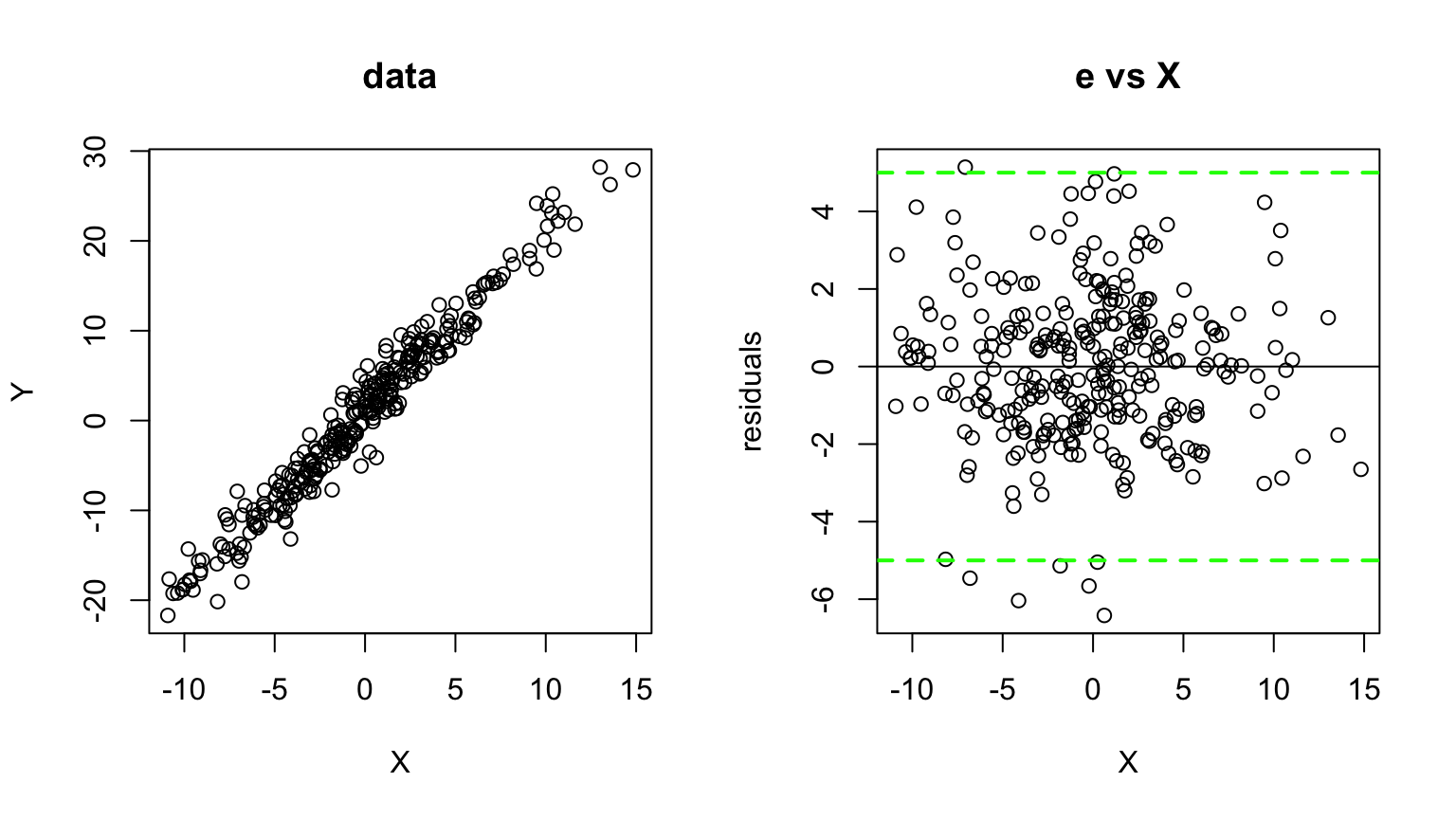
The regression lines and \(R^2\) values are the same…
b0
b1
R2
1
3.000
0.500
0.667
2
3.001
0.500
0.666
3
3.002
0.500
0.666
4
3.002
0.500
0.667
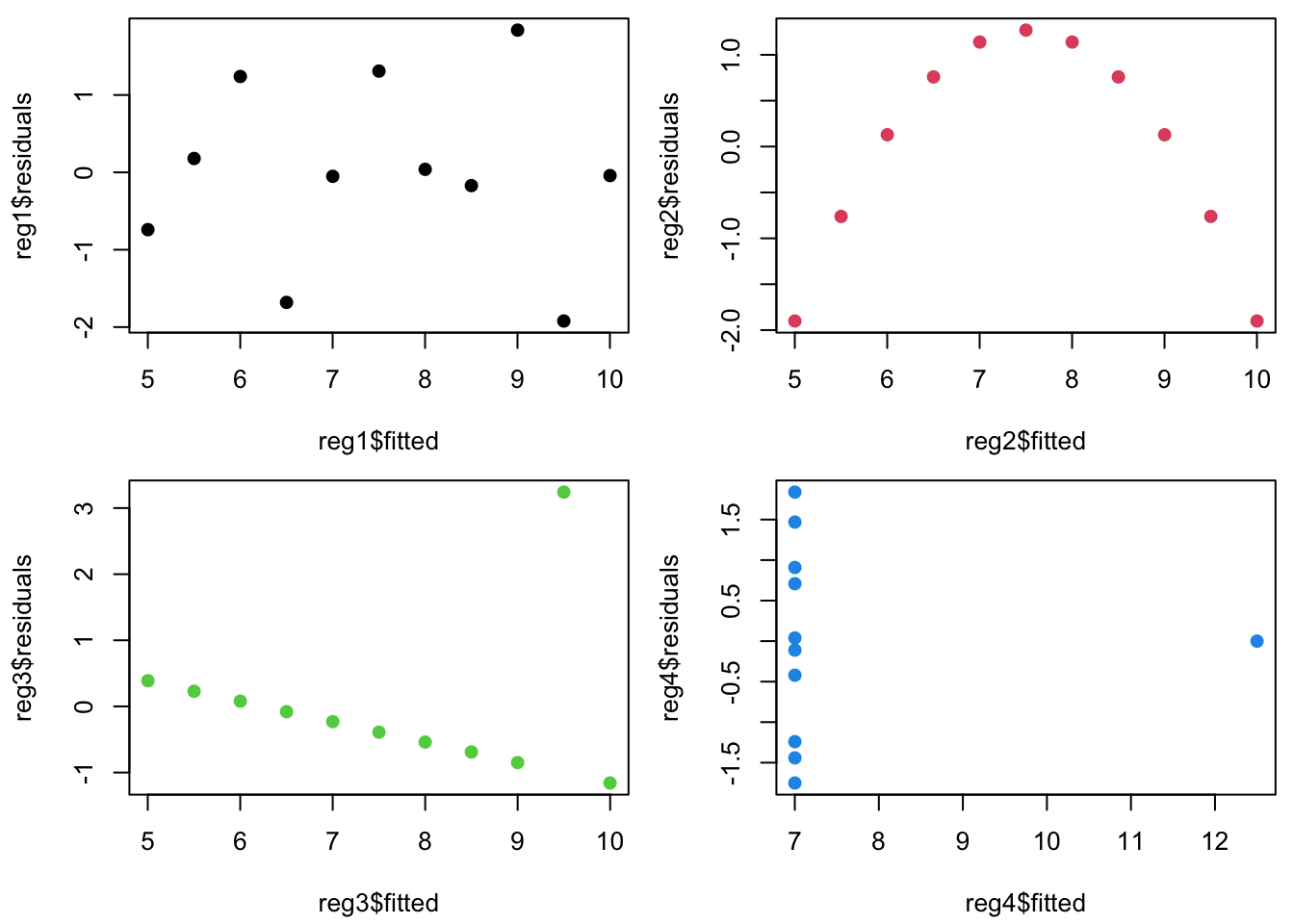
…but the residuals, \(e\), (plotted vs.\(\hat{Y~}\)) look totally different.
Plotting residuals vs fitted values (\(e\) vs \(\hat{Y~}\)) is your #1 tool for finding fit problems.
Why?
Because it gives a quick visual indicator of whether or not the SLR assumptions are true.
What should we expect to see if they are true?
Residuals and the model assumptions
Recall that the linear regression model assumes \[
Y_i =\beta_0 + \beta_1 X_i + \varepsilon_i,~~\mbox{where}~~
\varepsilon_i \stackrel{iid}{\sim} \mathcal{N}(0,\sigma^2).
\]
Our goal is to determine if the “true” residuals are iid normal and unrelated to \(X\). If the SLR model assumptions are true, then the residuals must be just “white noise”:
Each \(\varepsilon_i\) has the same variance (\(\sigma^2\)).
Each \(\varepsilon_i\) has the same mean (0).
All of the \(\varepsilon_i\) have the same normal distribution.
How do we check these?
Well, the true \(\varepsilon_i\) residuals are unknown, so must look instead at the least squares estimated residuals.
We estimate \(Y_i = b_0 + b_1 X_i + e_i\), such that the sample least squares regression residuals are \(e_i = Y_i -\hat{Y~}_i\)
What should the \(e_i\) residuals look like if the SLR model is true?
Visually – first we check the residuals vs the predictor/fitted:
Mathematically – If the SLR model is true, it turns out that: \[
\color{red}{e_i \sim \mathcal{N}(0, \sigma^2 [1-h_i])},~~\color{red}{h_i = \frac{1}{n} + \frac{(X_i - \bar{X})^2}
{\sum_{j=1}^n (X_j - \bar{X})^2}}.
\]
The \(h_i\) term is referred to as the \(i^{th}\) observation’s leverage:
It is that point’s share of the data (\(1/n\)) plus its proportional contribution to variability in \(X\).
Notice that as \(n \rightarrow \infty\), \(h_i \rightarrow 0\) and residuals \(e_i\) “obtain” the same distribution as the unknown errors \(\varepsilon_i\), i.e., \(e_i \sim N(0, \sigma^2)\).
Understanding Leverage
The \(h_i\) leverage term measures sensitivity of the estimated least squares regression line to changes in \(Y_i\).
The term “leverage” provides a mechanical intuition:
The farther you are from a pivot joint, the more torque you have pulling on a lever.
Here is a nice online (interactive) illustration of leverage:
\(\Rightarrow\) One big outlier can make \(s\) over-estimate \(\sigma\).
Studentized residuals
We thus define a standard Studentized residual as \[
r_i = \frac{e_i}{s_{-i} \sqrt{1-h_i} }\sim t_{n-p-1}(0, 1)
\] where \(s_{-i}^2 = \frac{1}{n-p-1}\sum_{j \neq i} e_j^2\) is \(\hat{\sigma~}^2\) calculated without\(e_i\).
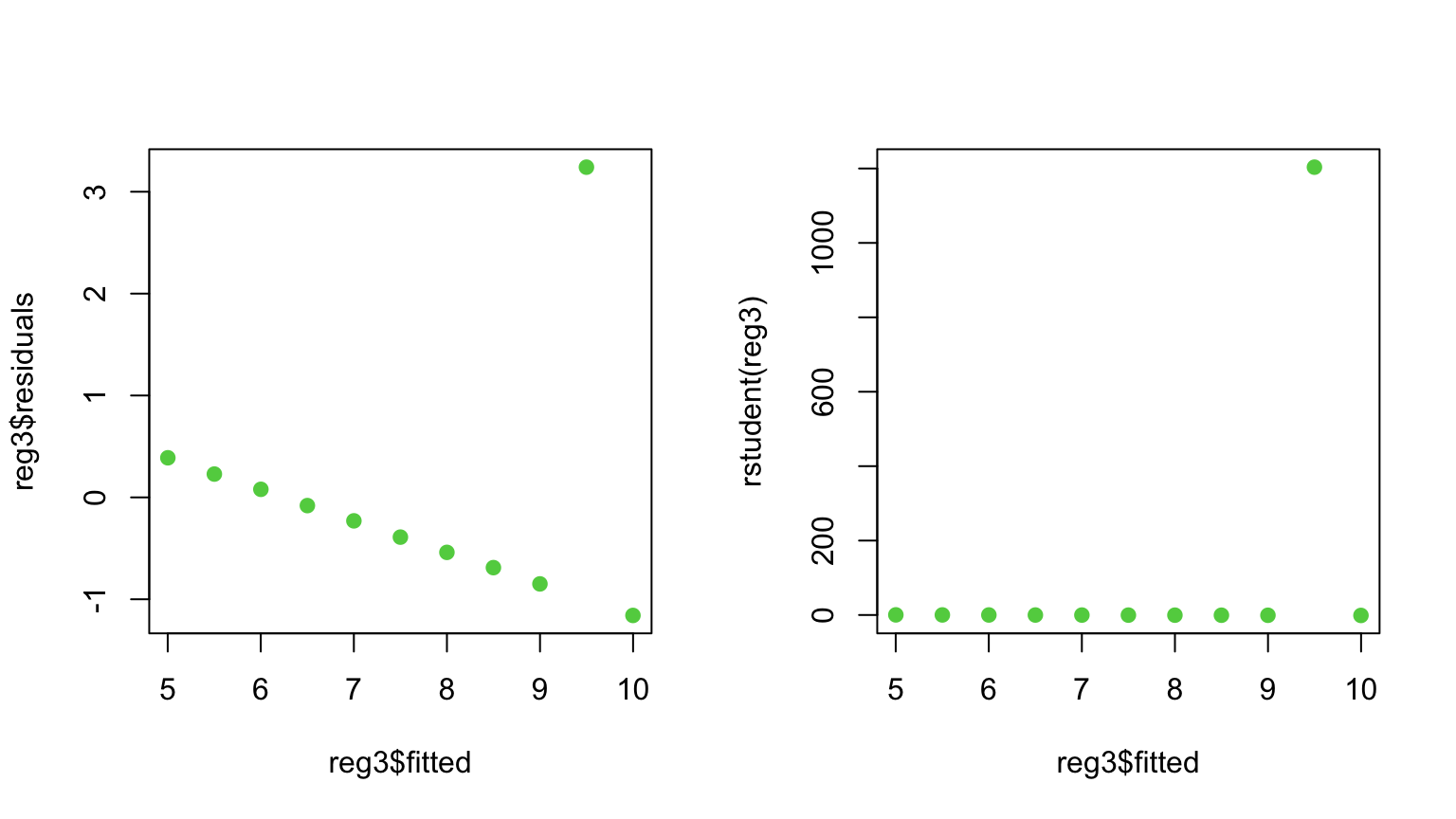
These are easy to get in R with the rstudent() function:
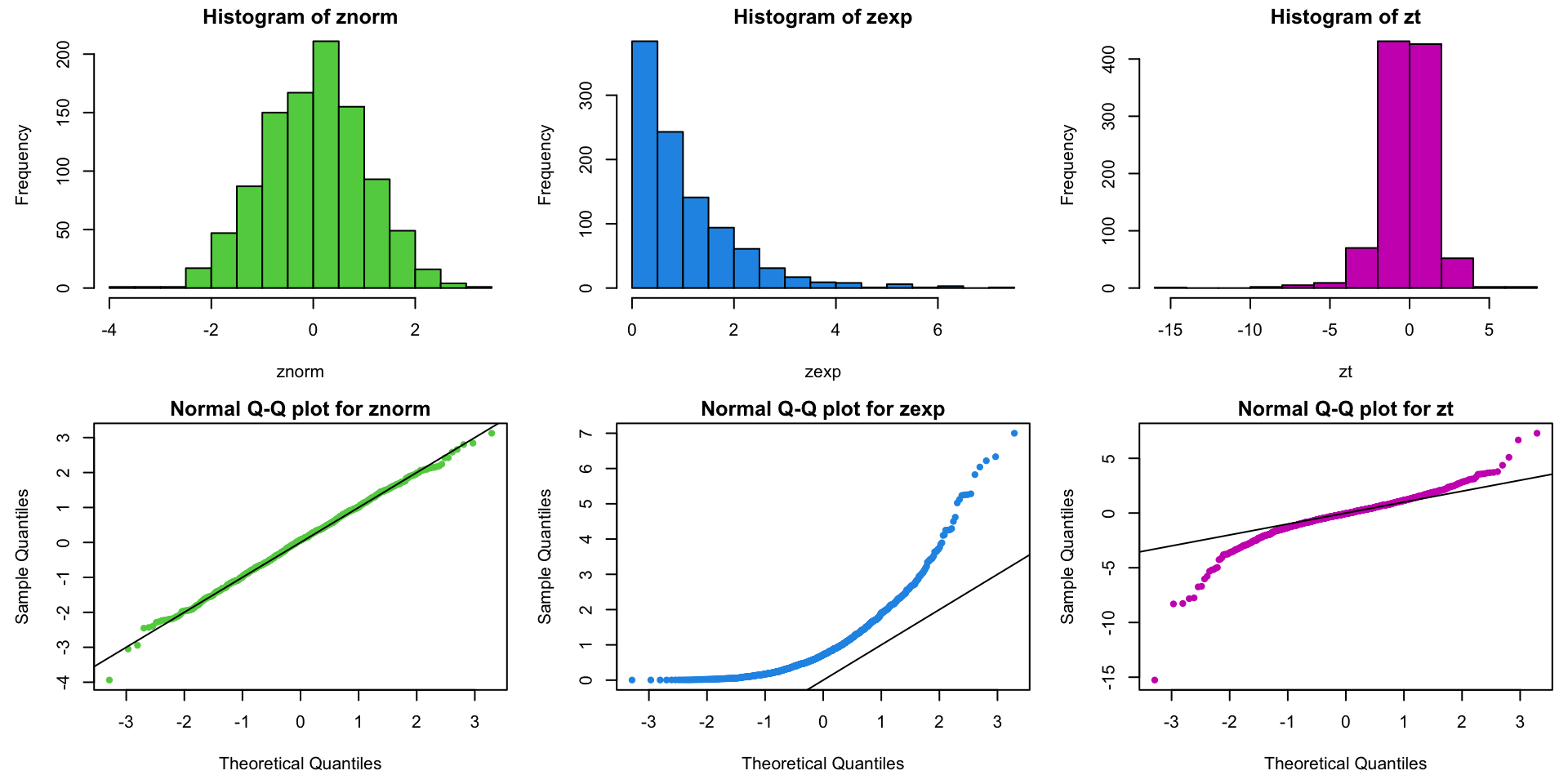
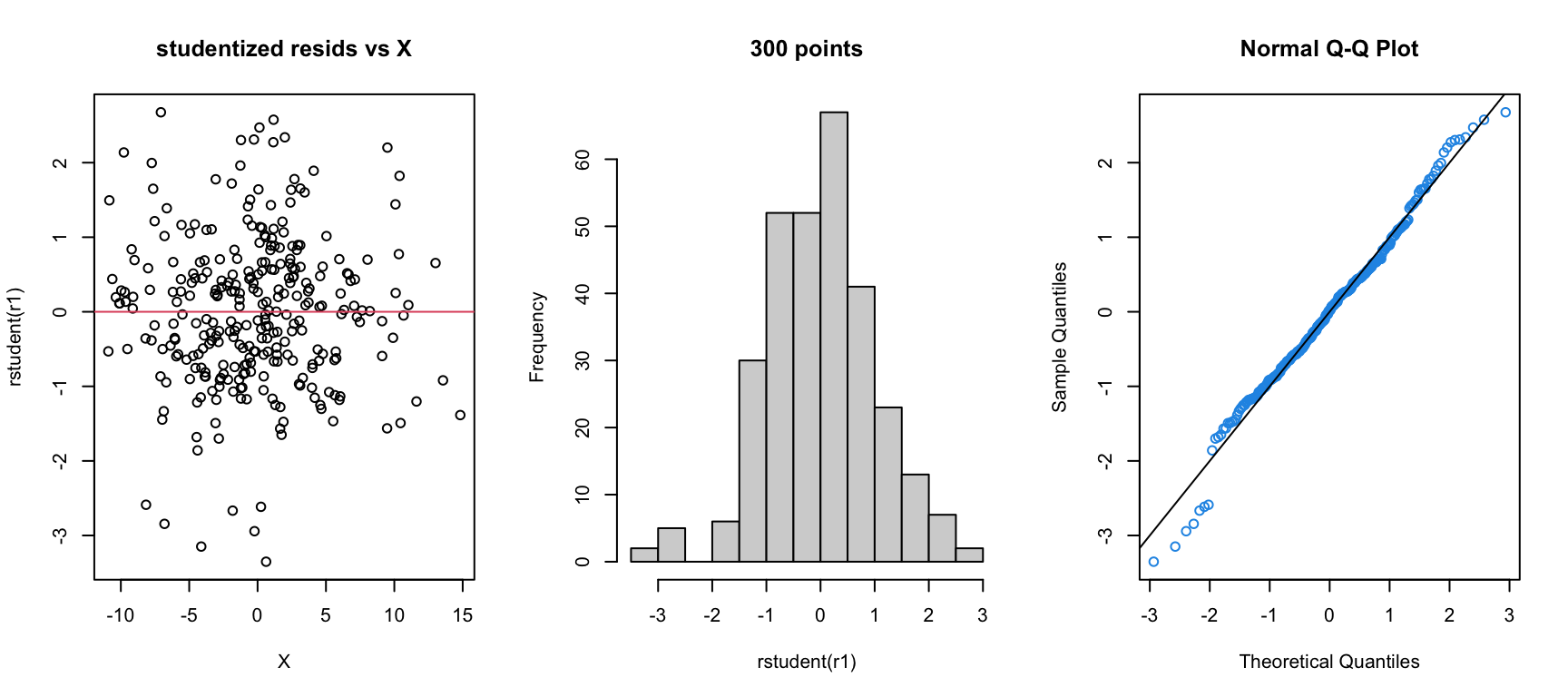
Since the studentized residuals are distributed \(t_{n-p-1}(0,1)\), we should be concerned about any \(r_i\) outside of about \([-2.5, 2.5]\).
(Note: As \(n\) gets much bigger, we will expect to see some very rare events (big\(\color{red}{\varepsilon_i}\)) and not get worried unless \(|r_i| > 3\) or \(4\).)
How to deal with outliers
from Research Wahlberg
How to deal with outliers
When should you delete outliers?
Only when you have a really good reason!
There is nothing wrong with running a regression with and without potential outliers to see whether results are significantly impacted.
Any time outliers are dropped, the reasons for doing so should be clearly noted.
I maintain that both a statistical and a non-statistical reason are required.
Outliers, leverage, and residuals
Warning:Unfortunately, outliers with high leverage are hard to catch through\(\color{dodgerblue}{r_i}\)(since the line is pulled towards them).
Means get distracted by outliers…
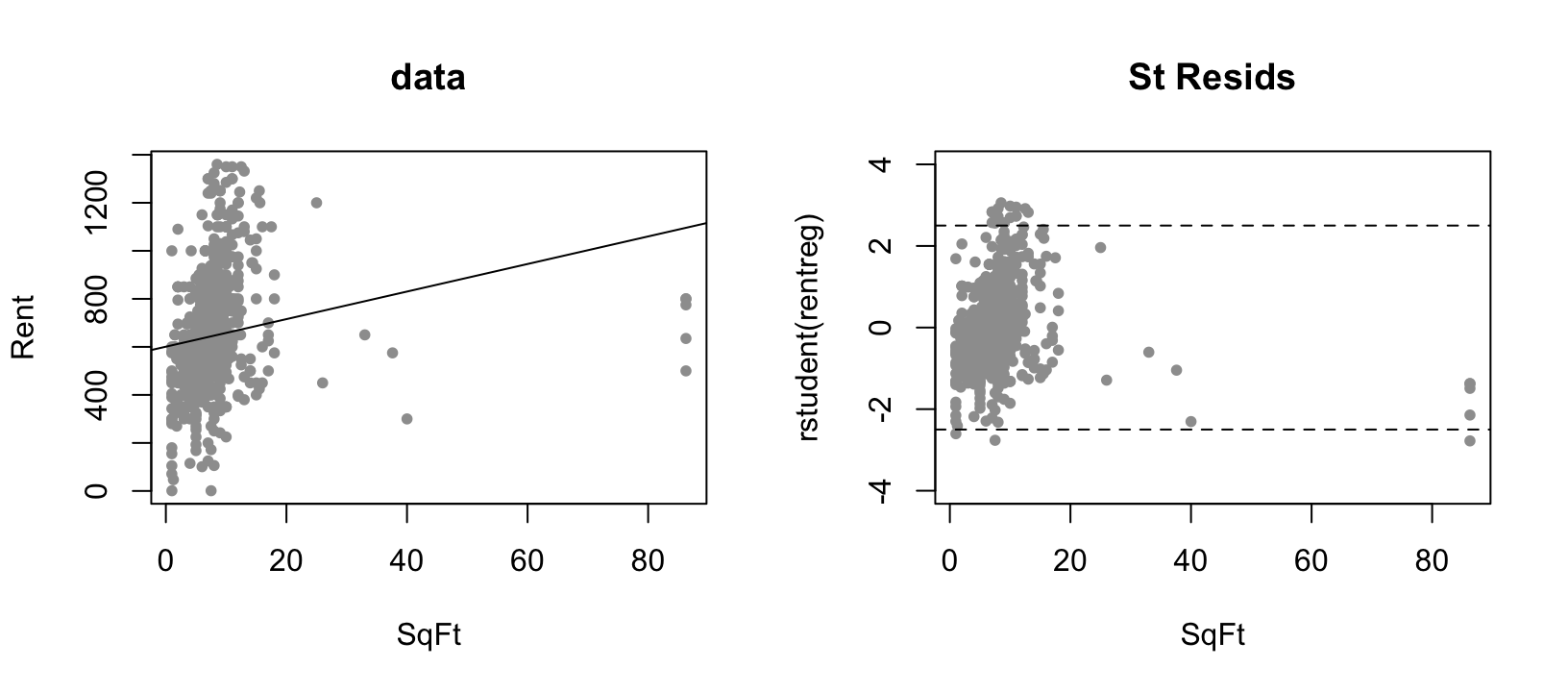
Outliers, leverage, and residuals
Warning:Unfortunately, outliers with high leverage are hard to catch through\(\color{dodgerblue}{r_i}\)(since the line is pulled towards them).
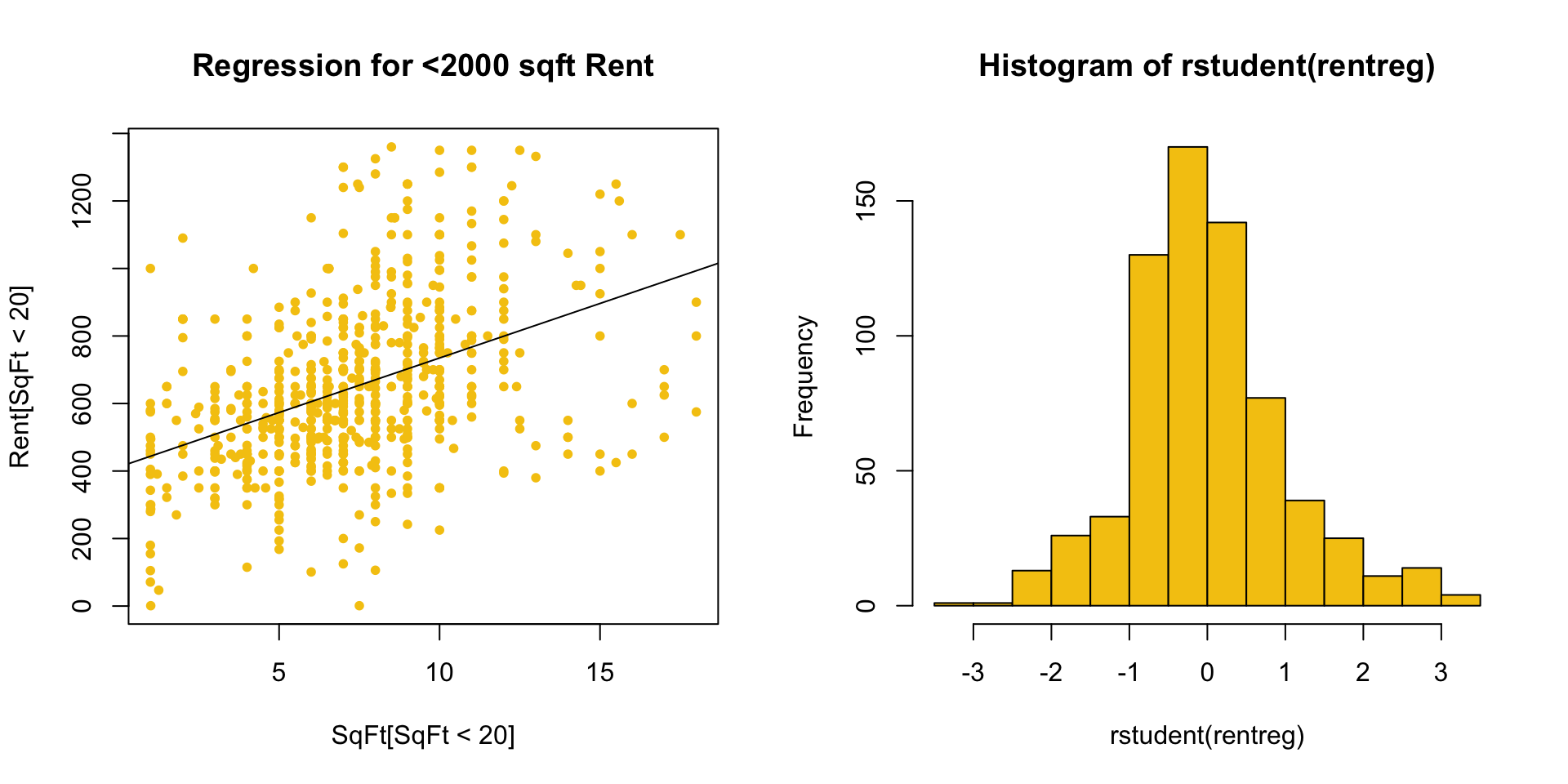
Consider data on house Rents vs SqFt:
Plots of \(r_i\) or \(e_i\) against \(\hat{Y~}_i\) or \(X_i\) are still your best diagnostic!
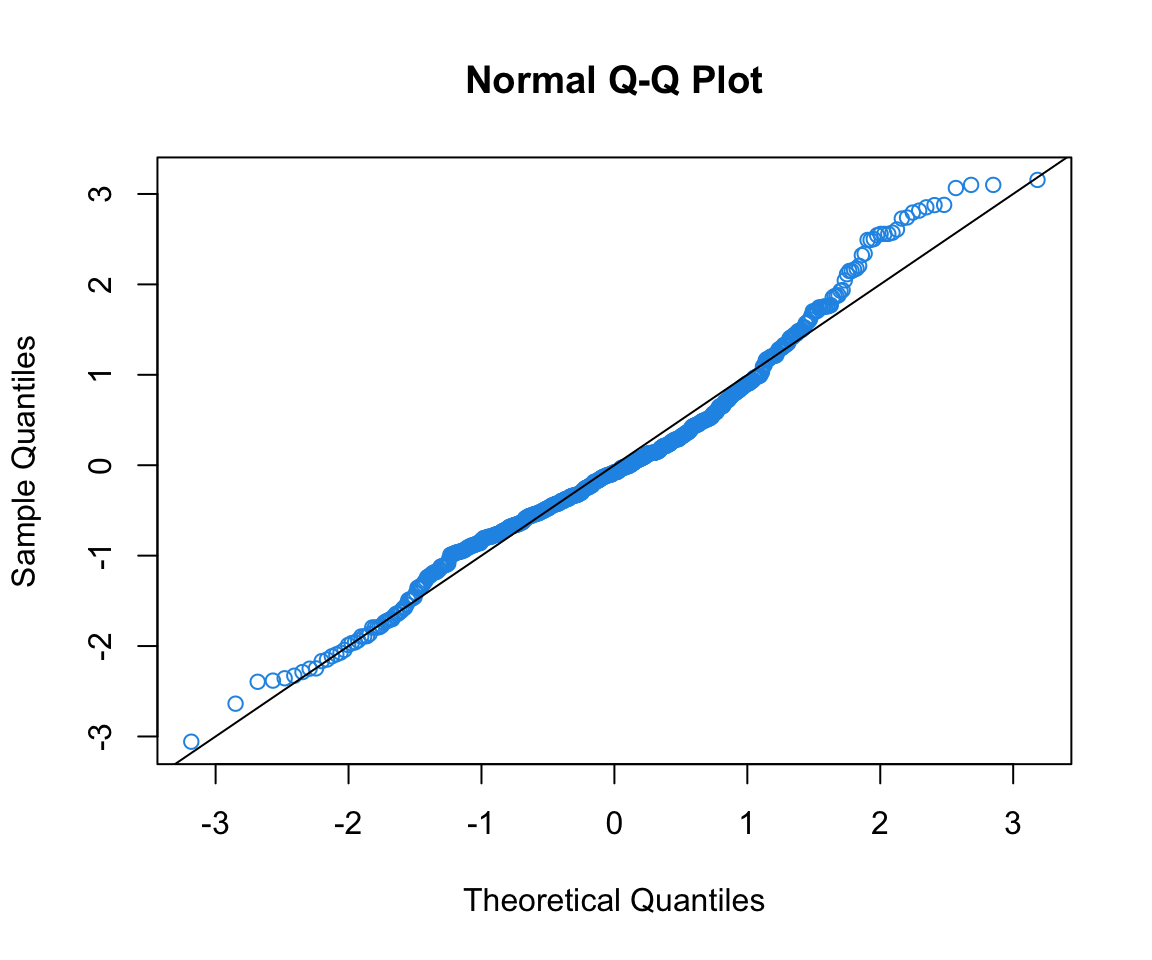
Normality and studentized residuals
A more subtle issue is the normality of the distribution on \(\varepsilon\).
We can look at the residuals to judge normality if \(n\) is big enough (say \(>20~~ \rightarrow\) less than that makes it too hard to call).
In particular, if we have decent size\(\color{red}{n}\), we want the shape of the studentized residual distribution to “look” like\(\color{red}{N(0,1)}\).
The most obvious tactic is to look at a histogram of \(r_i\).
For example, consider the residuals from a regression of Rent on SqFt which ignores houses with \(\geq 2000\) sqft.
identically distributed (i.e., they have constant variance)
All of these can be violated! Let’s see what violations look like and how we can deal with them within the SLR framework.
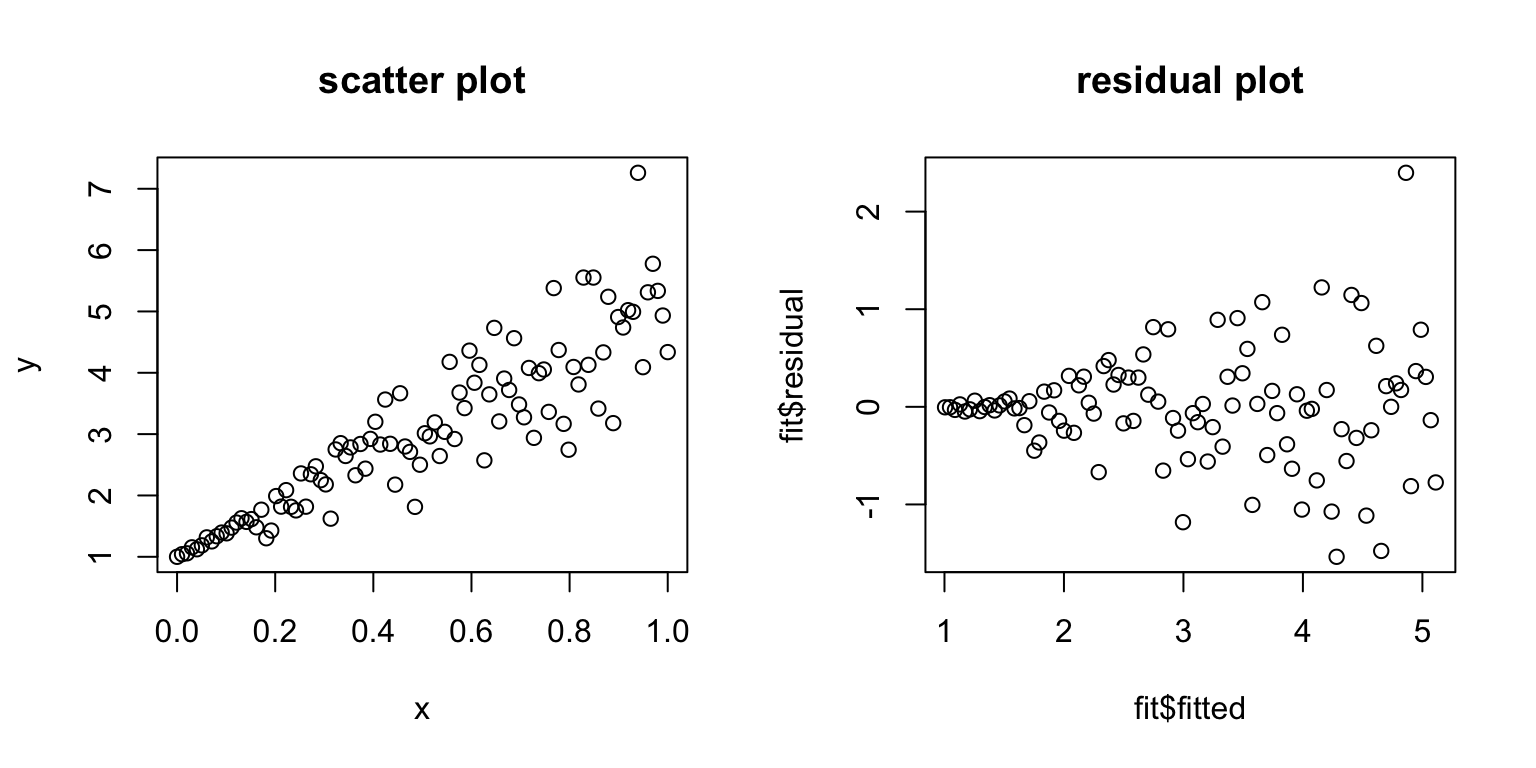
Violation 1: Non-constant variance
If you get a trumpet shape (bunching of the \(Y\)s), you have nonconstant variance.
This violates our assumption that all \(\varepsilon_i\) have the same \(\sigma^2\).
Solution 1: Variance stabilizing transformations
This is one of the most common model violations; luckily, it is usually fixable by transforming the response (\(Y\)) variable.
\(\color{dodgerblue}{\log(Y)}\) is the most common variance stabilizing transform.
If \(Y\) has only positive values (e.g. sales) or is a count (e.g. # of customers), take \(\log(Y)\) (always natural log).
\(\color{dodgerblue}{\sqrt{Y}}\) is sometimes used, especially if the data have zeros.
In general, think what you expect to be linear for your data.
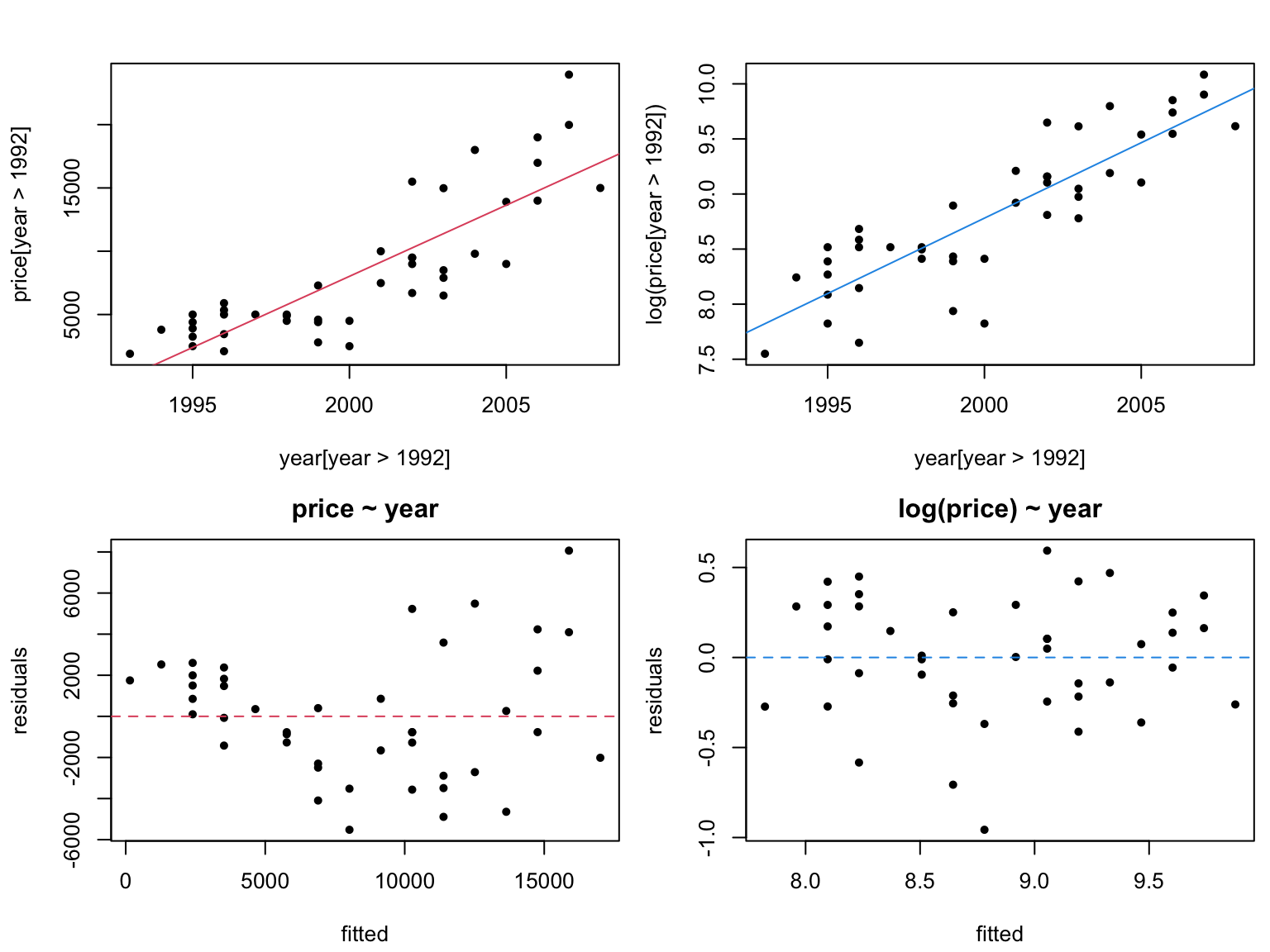
Reconsider the regression of truck price onto year, after removing trucks older than 15 years (truck[year>1992,]).
Warning: be careful when interpreting transformed models.
If \(\mathbb{E}[\log(Y)] = b_0 + b_1 X\), then \(\mathbb{E}[Y] \approx e^{b_0} e^{b_1 X}\).
We have a multiplicative model now!
Note: you CANNOT compare\(R^2\) values for regressions corresponding to different transformations of the response.
\(Y\) and \(f(Y)\) may not be on the same scale,
therefore \(\text{var}(Y)\) and \(\text{var}(f(Y))\) may not be either.
Instead, look at residuals to see which model is better.
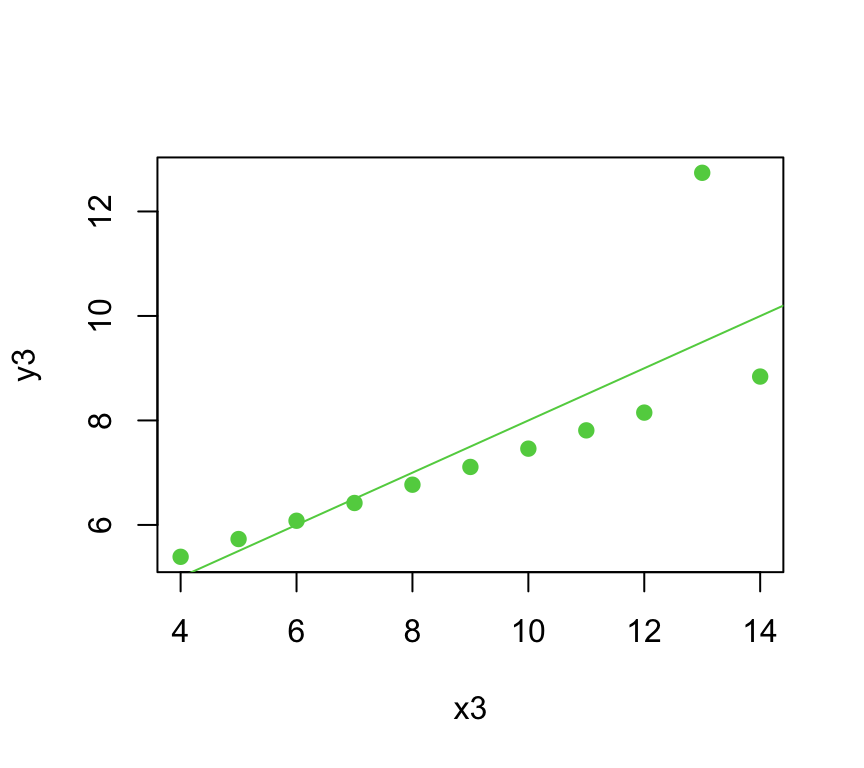
Violation 2: Nonlinear residual patterns
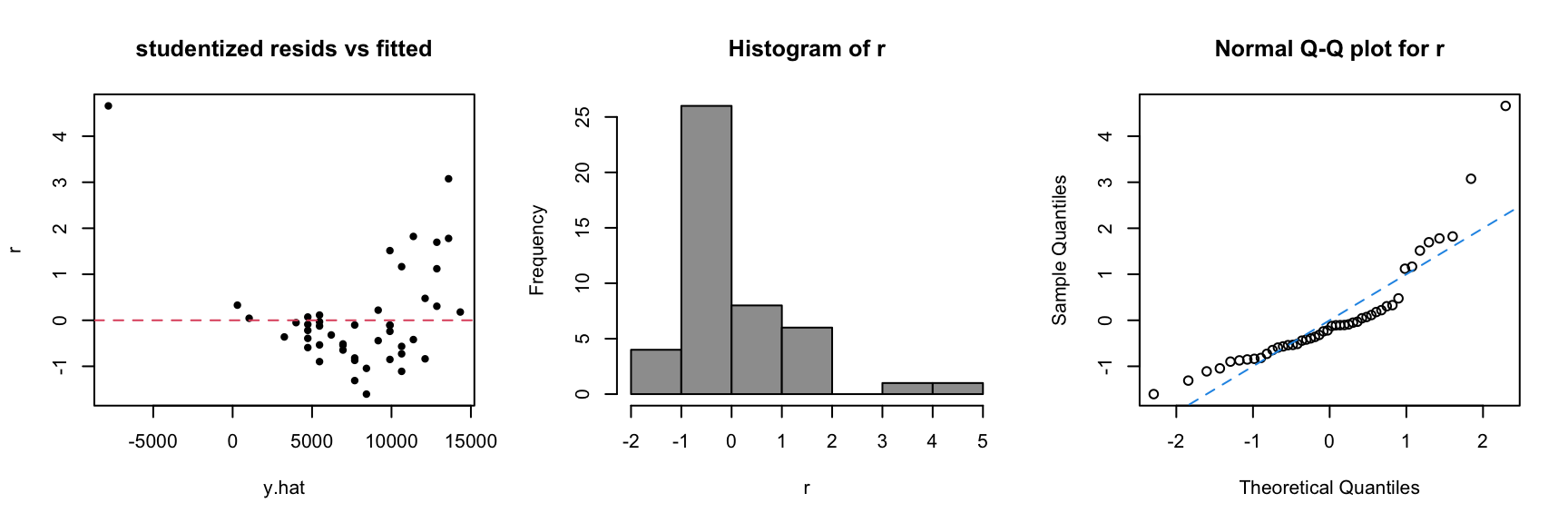
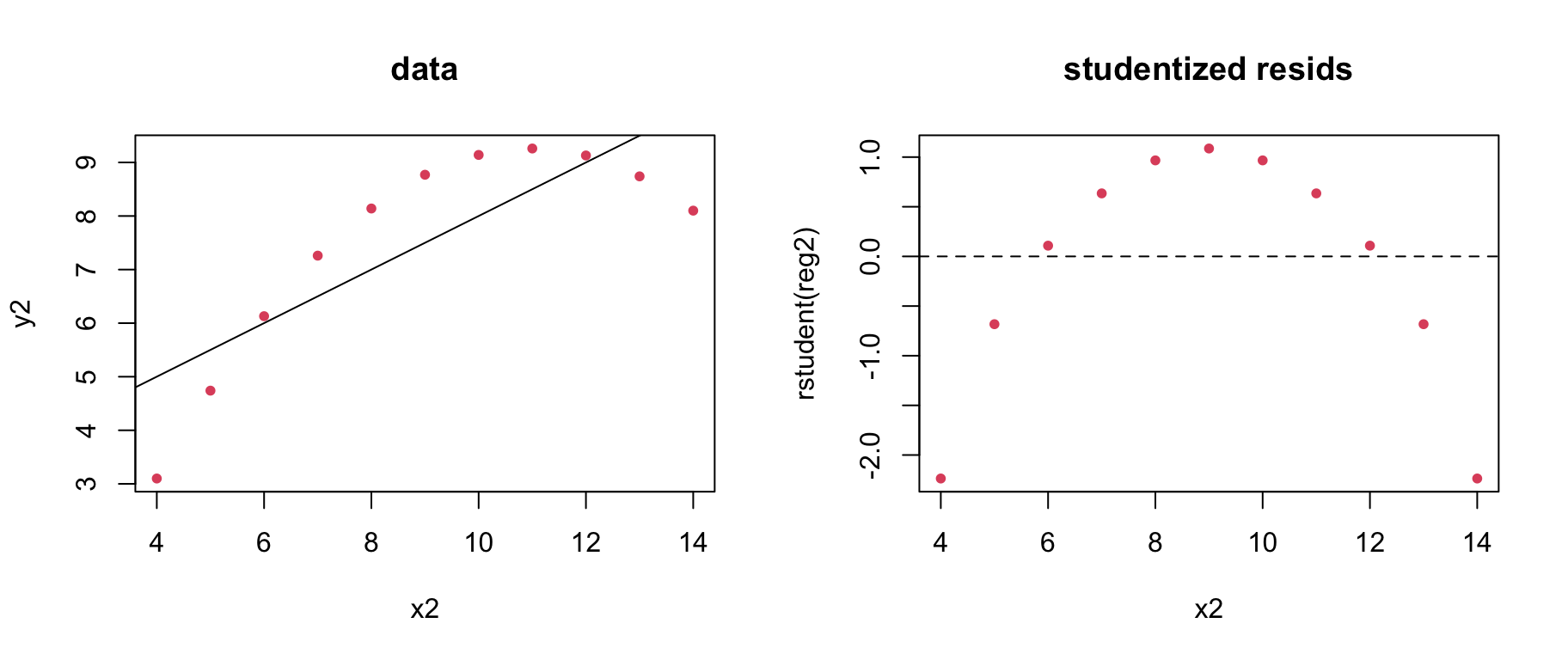
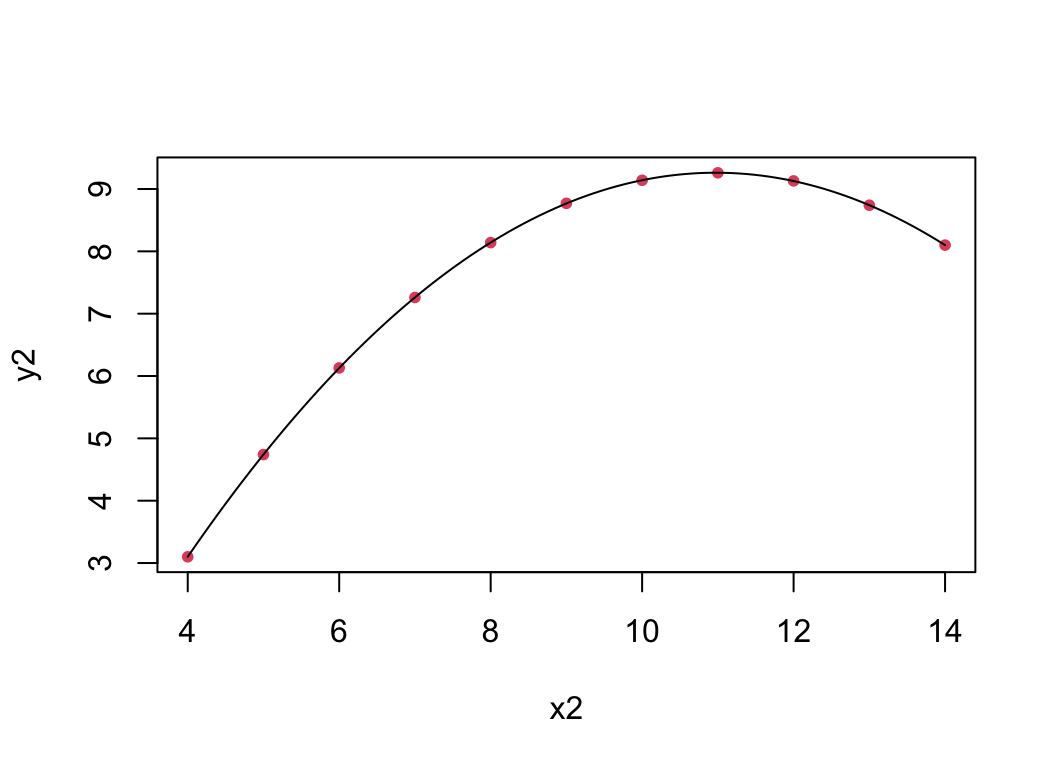
Consider regression residuals for the 2nd Anscombe dataset:
Things are not good! It appears that we do not have a linear mean function; that is \(\color{dodgerblue}{\mathbb{E}[Y] \neq \beta_0 + \beta_1 X}\).
Solution 2: Polynomial regression
Even though we are limited to a linear mean, it is possible to get nonlinear regression by transforming the \(X\) variable.
In general, we can add powers of\(\color{dodgerblue}X\) to get polynomial regression: \(\color{red}{\mathbb{E}[Y] = \beta_0 + \beta_1X + \beta_2 X^2 + \cdots + \beta_m X^m}\)
You can fit any mean function if \(m\) is big enough.
Usually stick to m=2 unless you have a good reason.
Try \(\mathbb{E}[Y] = \beta_0 + \beta_1 X + \beta_2 X^2\) for Anscombe’s 2nd dataset:
To see if you need more nonlinearity, try the regression which includes the next polynomial term, and see if it is significant.
For example, to see if you need a quadratic term,
fit the model then run the regression \(\mathbb{E}[Y] = \beta_0 + \beta_1 X + \beta_2 X^2\).
If your test implies\(\color{dodgerblue}{\beta_2 \neq 0}\), you need\(\color{dodgerblue}{X^2}\) in your model.
Note: \(p\)-values are calculated “given the other \(\beta\)’s are nonzero”; i.e., conditional on \(X\) being in the model.
Closing comments on polynomials
We can always add higher powers (cubic, etc.) if necessary.
If you add a higher order term, the lower order term is kept in the model regardless of its individual \(t\)-stat.
Be very careful about predicting outside the data range as the curve may do unintended things beyond the data.
Watch out for over-fitting.
You can get a “perfect” fit with enough polynomial terms,
but that doesn’t mean it will be any good for prediction or understanding.
Other problems
Sometimes we have other strange things going on in our data sets
data are “clumped” up in \(X\) – high leverage points
residuals still aren’t normally distributed after taking transforms from earlier
responses take discrete values instead of continuous
The latter 2 we can deal with using MLR and GLMs. What about the first?
The log-log model
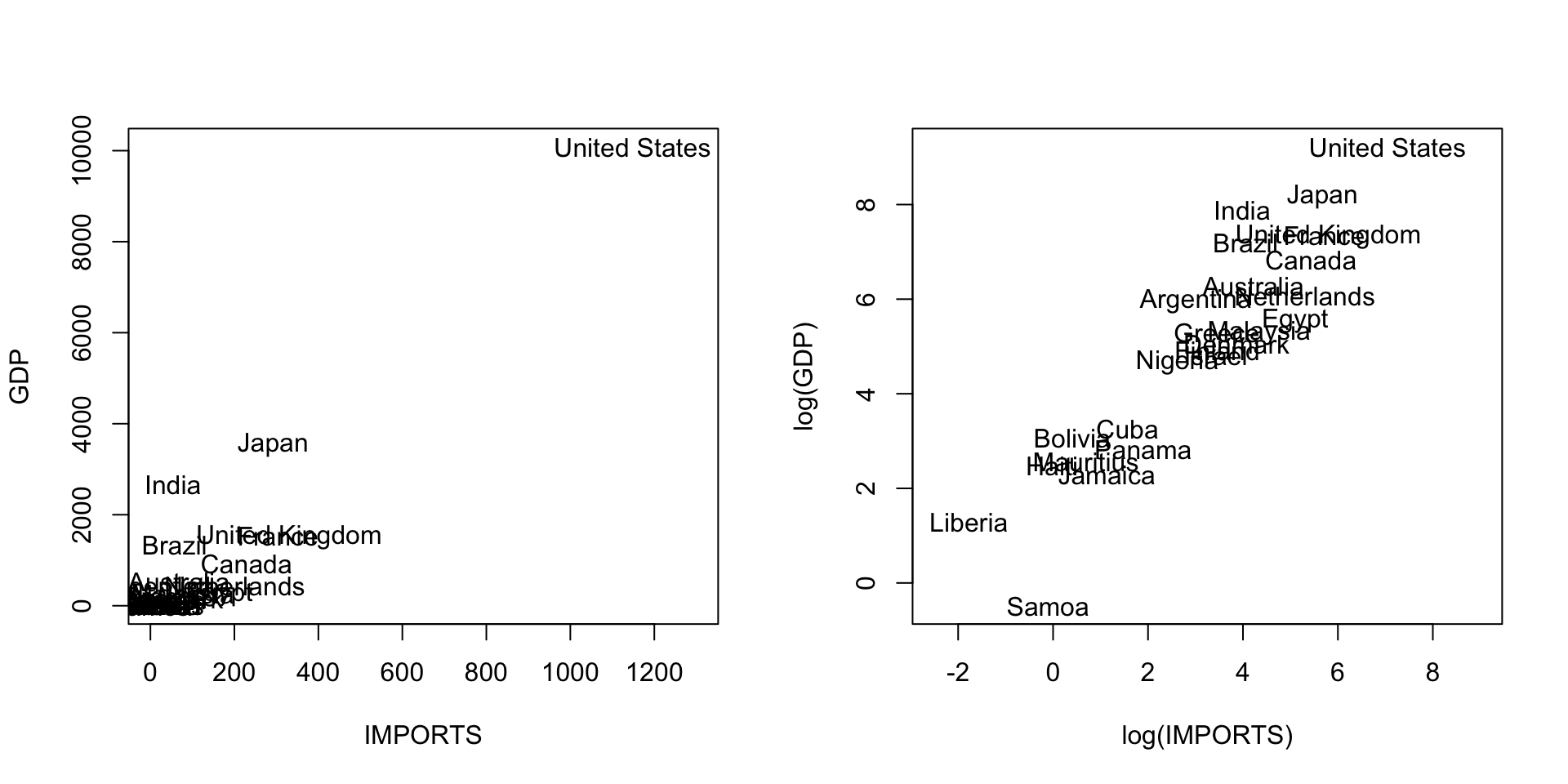
The other common covariate transform is \(\log(X)\).
When \(X\)-values are bunched up, \(\log(X)\) helps spread them out and reduces the leverage of extreme values.
Recall that both reduce \(s_{b_1}\).
In practice, this is often used in conjunction with a \(\log(Y)\) response transformation. The log-log model is \[
\color{red}{\log(Y) = \beta_0 + \beta_1 \log(X) + \varepsilon}.
\]
It is super useful, and has some special properties …
Consider the multiplicative model \(\color{red}{\mathbb{E}[Y|X] = AX^B}\).
Take logs of both sides to get \[
\color{red}{
\begin{aligned}
\log(\mathbb{E}[Y|X]) = \log(A) + \log(X^B) &= \log(A) + B\log(X) \\
&\equiv \beta_0 + \beta_1 \log(X).
\end{aligned}
}
\]
The log-log model is appropriate whenever things are linearly related on a multiplicative, or percentage, scale.
Consider a country’s GDP as a function of IMPORTS:
Since trade multiplies, we might expect to see %GDPincrease with %IMPORTS.
Elasticity and the log-log model
In a log-log model, the slope \(\beta_1\) is sometimes called elasticity.
The elasticity is (roughly) % change in \(Y\) per 1% change in \(X\). \[\color{dodgerblue}{
\beta_1 \approx \frac{d\%Y}{d\%X}}\] For example, economists often assume that GDP has import elasticity of 1. Indeed: